
financial-risk-LLM
本文是我的毕设项目,由于是从24年6月到25年5月陆陆续续迭代出来的,项目过于屎山,在王某的督促下重头开始复刻一遍流程
项目简介
毕设项目为金融风险大模型及系统开发。详细指对所选公司的财务报表及新闻舆情结合分析得出综合性的分数,再通过简单的可视化网站输出到前端
关于新闻舆情部分,简单来说就是对新闻进行情感分类任务。本文针对Meta-Llama-3.1-8B-bnb-4bit模型进行修改微调。在模型方面加入特征值和全局语义的双通道系统和生成-分类模型头。在参数调优方面加入LoRA并进行分层解冻。在模型训练方面加入部分回调代码。
在结合财务报表及新闻舆情部分,使用Altman-z-score计算财务报表的分数。对每日新闻进行时序分数衰减后得出的每日情感分数相加再和财务报表的z-score分数权重相加。得出最后的结果。\
环境配置
1 | torch==2.5.1+cu121 |
本文是在unsloth-llama-3-8b-bnb-4bit的初始指导文章的基础下进行修改的
unsloth原文解释
先解释一下unsloth-llama-3-8b-bnb-4bit的原文
1 | from unsloth import FastLanguageModel |
这段的目的是加载经过unsloth量化后的模型,原文在colab运行,可以直连到huggingface,由于墙的原因,直接运行时无法与http://huggingface.io取得联系,建议通过镜像下载模型后本地导入模型。
1 | model = FastLanguageModel.get_peft_model( |
这段是加载了LoRA进行参数微调。众所周知,LoRA可以大幅减少所需要更新的参数。这在我们小规模训练微调方面十分重要。
采用r=16(指LoRA rank,越大越精准,同时训练的参数也越高,在大多数任务中,当秩达到8或16时,模型性能(如准确率、困惑度)已接近全参数微调(Full Fine-tuning)的水平。)
参考文献:Hu E J, Shen Y, Wallis P, et al. Lora: Low-rank adaptation of large language models[J]. ICLR, 2022, 1(2): 3.
针对投影层中的[“q_proj”, “k_proj”, “v_proj”, “o_proj”,”gate_proj”, “up_proj”, “down_proj”]模块进行微调,
lora_alpha = 16,lora_alpha是一个用于缩放LoRA更新的系数。在计算权重更新$\Delta W$时,它起到调整更新幅度的作用
$\Delta W = \frac{\text{lora alpha}}{r} AB$
random_state 指随机种子,固定种子可以保证运行结果可复现
1 |
|
这是提示词模板,可以根据你所需要的领域迁移修改提示词
1 | from datasets import load_dataset |
这就是正式的开始训练的主流程了。
下面详细解析传入SFTTrainer的参数:
model:即先前加载的语言模型对象
tokenizer:是与模型关联的分词器对象,用于处理文本数据。
train_dataset:这是用于训练的数据集,
dataset_text_field:指定数据集中包含训练文本数据的列名,在此例中为 “text”。
max_seq_length:设定处理输入数据的最大序列长度,有助于在训练时控制内存使用。
dataset_num_proc:确定用于数据加载和预处理的进程数量,增加进程数可加快数据准备速度。
args:传入TrainingArguments对象,其中包含训练过程的详细配置。
下面看看TrainingArguments对象中的参数:
per_device_train_batch_size:设定每个设备(如 GPU)上的训练批量大小,较小的批量所需内存更少,同时更慢。
gradient_accumulation_steps:该参数允许在执行一次优化步骤前,对多个较小批量的梯度进行累积,这样能在不增加单个批量内存需求的情况下,有效增大整体批量大小。
warmup_steps:指定训练开始时线性预热阶段的步数,在此阶段学习率会逐渐提高。
max_steps:设定要执行的总训练步数,在\这段代码中设为 60,是出于演示目的。若要进行完整训练,通常应设置train_epochs,而将max_steps设为None。
learning_rate:优化器使用的学习率。
logging_steps:指定记录训练进度(如损失值、学习率)的频率,这里每 1 步记录一次。
optim:训练使用的优化器,”adamw_8bit” 是一种节省内存的 AdamW 优化器。
weight_decay:正则化参数,对较大的权重进行惩罚。
lr_scheduler_type:使用的学习率调度器类型,”linear” 表示学习率在预热阶段后将线性下降。
seed:设置随机种子以确保结果可重现。
output_dir:保存训练输出(如检查点和日志)的目录。
数据集构建
由于网上并没有中文现成的标注好的数据集,因此要自己构建
最初是想要从金融choice数据copy数据集,however,24年时候还可以500条一次复制一页的数据(直接导入数据有次数限制,可以直接在页面复制数据到excel表格),到了25年时候只能50条一页的复制数据了,非常的麻烦,就写了个简单的爬虫爬取东方财富网股吧资讯页面的数据
下面是部分代码
非结构化数据集
1 | # 股票代码和名称映射 |
由于股吧本身页面的url并没有显示年份,所以自己设置了一个推断年份的部分:默认第一页数据是今年的,越往后月份越大,直到月份转为1月,这时候认为是去年的,年份减一
从当前元素(item)下查找所有 <div class=”title”> 的子元素,再向下递归查找所有 <a> 标签的 href 属性。返回一个列表(即使只有一个元素)。link[0] 表示只取第一个匹配的链接(假设目标页面中每个标题只有一个有效链接)。strip() 用于清理链接两端的空格或换行符。然后补全链接
你要分析哪个数据的公司的数据就爬公司的数据,再爬点其他公司的数据给:deepseek,让deepseek给你”人工”标注数据最后7:3形成训练集和验证集
训练集和验证集
收集好的训练集和验证集like:
1 | time,text,label |
待处理新闻
收集好的待处理新闻like:
1 | time,text |
结构化数据集
随便找个网站就能找到上市企业的季度的财务报表,这里我们主要使用利润表和资产负债表中的部分数据来计算Altman-z-score
| Altman Z-Score | 所需数据项 | 来源报表 | 具体字段名称 |
|---|---|---|---|
| X₁ | 流动资产 | 资产负债表 | 流动资产合计 |
| X₁ | 流动负债 | 资产负债表 | 流动资产合计 |
| X₁ | 总资产 | 资产负债表 | 流动负债合计 |
| X₂ | 留存收益 | 资产负债表 | 储备 |
| X₂ | 总资产 | 资产负债表 | 总资产 |
| X₃ | 息税前利润 | 利润表 | 营业利润+利息支出–利息收入 |
| X₃ | 总资产 | 资产负债表 | 总资产 |
| X₄ | 股东权益 | 资产负债表 | 股东权益合计 |
| X₄ | 总负债 | 资产负债表 | 总负债合计 |
| X₅ | 营业总收入 | 利润表 | 营业总收入 |
| X₅ | 总资产 | 资产负债表 | 总资产 |
金融情绪分析模型
最初并没有对模型本身进行修改,被导师狠狠的拷打,于是参考FinBERT: A Large Language Model for Extracting Information from Financial Text 添加了一个生成转分类模型头。参考过往的金融新闻文本,添加了一堆关键词(金融新闻感觉没什么新东西),对金融文本提取[积极,中性,消极]向量,和本身大模型注意力机制融合,输出情感分类。
下面是部分关键代码
模型增强架构
1 | class EnhancedLlamaClassifier(torch.nn.Module): |
模型继承torch.nn.Module,包含三个核心组件:
LoRA适配器:轻量级微调预训练模型,典型LoRA实现模式:只训练LoRA参数,保持原始模型参数冻结。
特征增强模块:处理外部特征,将离散关键词特征映射到与文本特征对齐的连续空间。模型会更精确的分析金融文本情感特征(十分好用)
分类器:综合两种特征进行分类
最后对不平衡的样本(看涨6000±,看跌2000±,中性1000±)进行交叉熵加权,缓解类别不平衡问题
模型回调函数
1 | # ================= 梯度监控 ================= |
在模型训练初期,训练效果一坨屎,梯度监控方便调参。选择L2范数而非最大值,避免极端值干扰
早停机制在保证模型准确率趋于最高时尽早结束因为AutoDL的机子针对很贵早停策略在保证模型性能的前提下,平均减少50分钟的无效训练。
训练主流程
1 | # ================= 数据加载 ================= |
在训练参数部分,物理批次2+梯度累积16的混合训练模式,相当于传统32批次的效果,但显存峰值明显降低。(32批次4090显卡最高20000的显存直接爆掉了,优化后也用了18000左右的显存)
学习率采用1.5e-4配合余弦退火策略,前20%训练步进行预热,减少了Transformer模型的梯度振荡问题。
AdamW优化器的β2=0.95设置,特别适配金融文本的长尾分布特性。”
Transformer模型由于自注意力机制,参数众多,训练时梯度可能会出现不稳定的波动,尤其是在不同层之间。比如,浅层和深层的梯度可能差异很大,导致优化过程中参数更新幅度不一致,出现震荡,影响收敛。这时候,优化器的选择就很重要,AdamW作为Adam的改进版本,能更好地处理权重衰减,避免过拟合。
AdamW中的β2参数控制的是梯度二阶矩的指数衰减率。默认β2通常是0.999,这样会考虑更长时间段的梯度平方,适用于平稳的梯度环境。但在金融文本中,数据分布长尾,即少数类别样本多,多数类别样本少,导致梯度变化大,尤其是小样本类别梯度可能突然出现较大的变化。如果β2设置较高,二阶矩估计会过于平滑,无法快速适应这些突然的变化,导致参数更新不够灵敏。降低β2到0.95,可以让二阶矩估计更快地反应最近的梯度变化,从而更灵活地调整学习率,对长尾数据中的稀疏但重要的信号(如罕见但关键的金融术语)有更好的适应性。
模型其他部分
1 | # ================= 关键词配置 ================= |
第一段看上去非常像关键词匹配,实际上其实也是关键词匹配(关键词匹配真的很好用qwq,最初的模型没有这部分准确率只有0.7,加上之后直奔0.95),怎么说呢,实际上这一部分应该换成其他的模式,比如金融知识图谱,把知识喂给大模型告诉它什么是正面的什么是中性的。但是我少了这一部分,尽管来说,达到的是一样的效果,有一点点偷工减料(bushi)
第二段是prompt工程;第三段是新闻预处理(一开始我使用的是huggingface上的twitter财经新闻数据集,有标注的,里面有很多其他的奇奇怪怪的符号,后来换成爬取的中文数据集用不上了,不过我没删倒是)
每日分数计算:$daily_score = \frac{正面新闻数量-负面新闻数量}{总数量}$
最后输出每天的情感分数,到这里,金融情感分析模型部分算是结束了
每日综合风险分数计算
财务报表得分Altman-z-score
经典计算方式:$Z = 0.717 * X1 + 0.847 * X2 + 3.107 * X3 + 0.42 * X4 + 0.998 * X5$
衰减每日情感得分
引入指数衰减机制模拟市场记忆规律——以0.7为衰减因子,5天为时间窗口构建情感时间透镜。计算公式中,第t-n天情感值权重为0.7ⁿ,使五天前的情绪影响仅为当前的1.6%,完美体现行为金融学的近因效应。
Bollen J, Mao H, Zeng X. Twitter mood predicts the stock market[J]. Journal of computational science, 2011, 2(1): 1-8.
1 | # 情感分数衰减计算 |
计算综合分数
综合分数就是简单的线性计算,让结构化分数为主,新闻舆情为辅
1 | results = [] |
可视化网站
可视化网站采用分层架构设计,前端基于Vue.js实现响应式交互,后端依托Flask框架提供RESTful API服务
最后完成截图like: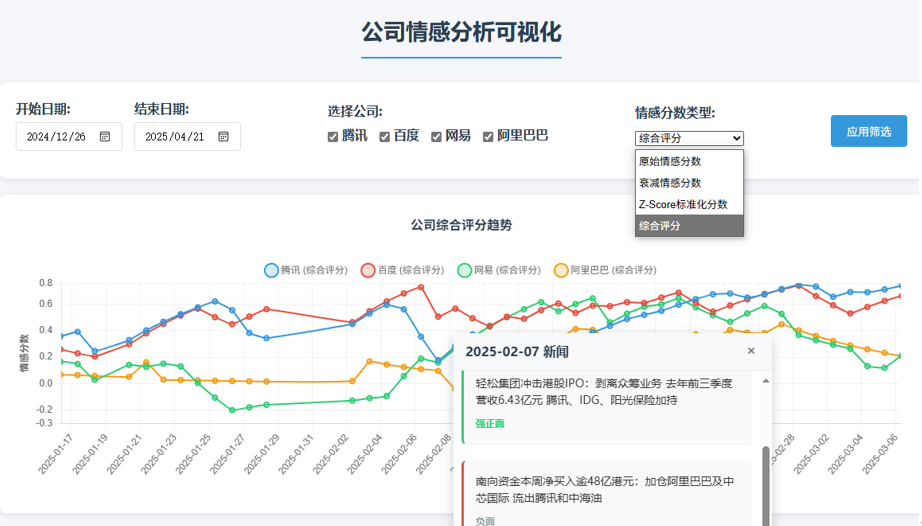
前端
仪表板初始化
1 | // 初始化页面 |
初始化页面加载,设置默认时间范围为”所有历史数据”,绑定筛选按钮和复选框的交互事件,首次加载数据触发整个应用启动
数据获取
1 | // 获取并更新数据 |
从指定位置获取所有数据,支持日期范围/公司选择/指标类型多维过滤
更新图表
1 | // 更新图表 |
这段代码的目的是更新并渲染一个图表,代码从页面中获取用户选择的情感指标类型,然后初始化一个空的数据集,用来存储图表需要的各个公司的数据。在准备数据的过程中,首先会对数据进行按日期排序,确保绘制的图表按时间顺序显示。
对于每个选中的公司,代码会遍历原始数据并提取出该公司对应的情感分数。如果该公司在某些日期没有数据,代码会跳过这些数据点,同时在控制台输出缺失数据的提醒。只要该公司有有效数据,就会将其加入到图表的数据集中。。
使用 Chart.js 创建一个新的折线图,并通过各种配置选项来定制图表的行为,比如X轴和Y轴的标签、显示格式、网格、刻度、图例、标题、工具提示等。
tooltip插件被用来显示详细的情感分数,当鼠标悬浮在图表上时,除了显示分数,还会根据情感分数的大小添加一些描述,如“强正面”、“弱负面”等
统计卡片
1 | // 更新统计信息 |
计算代码中的信息并在网站最下面贴出统计信息
后端
1 | def get_composite_data(start_date, end_date, companies, sentiment_type): |
后端是四个相似的推送数据的代码,选取了一个推送综合分数的作为代表
总的来说是读取各个维度的csv文件,针对文件数据和格式采用不同的方式处理后,
总结
本文也算是第一批做中文大模型预测金融风险分析的了,开题当时网上还没有相关的数据和新闻报道(除了23年的招联搞得招联智鹿)。在文本中期时中文大模型预测金融风险便如雨后春笋,25年已经有很多较为成熟的产品了。
本文仅仅在新闻舆论部分取得了及格的结果(准确率:94.8%,召回率:94.7%,F1-score:94.7%)整体仍有许多不足之处,在新闻情感分析部分应该添加识别新闻主体的算法;公司财报任不能实时的展现结构化的风险;对于更多异构数据还需要结合考虑;本文部分公式未经消融实验亟需最优解;本文的训练集及验证集仍需更大规模的扩充;关键词还可以随时间增加规模等等,只可惜可能不会再优化了。